1. Hàm SLOPE()
Tìm hệ số góc của đường thẳng hồi
quy bằng cách sử dụng các điểm dữ liệu
trong known_y's và known_x's.
Ở bài hàm INTERCEPT(), tôi có viết: phương trình giao
điểm của đường thẳng hồi quy là:
(trong đó b là hệ số góc):
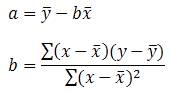
Với:
![]()
Hàm SLOPE() chính là hàm để xác
định cái b ở trên.
Cú pháp: = SLOPE(known_y's,
known_x's)
Known_y's :
Tập hợp các dữ liệu phụ thuộc.
Known_x's :
Tập hợp các dữ liệu độc lập.
Lưu ý:
o Đối số
phải là số, tên, mảng, hay tham chiếu đến
các ô chứa số.
o Nếu các đối
số là mảng hay tham chiếu có chứa các giá trị
text, logic, hay ô rỗng, thì các giá trị đó sẽ
được bỏ qua; tuy nhiên, ô chứa giá trị zero
(0) thì vẫn được tính.
o Nếu known_y's, known_x's
là rỗng hay chứa số điểm dữ liệu khác
nhau, SLOPE() trả về giá trị lỗi #NA!
o Giải thuật
của hàm SLOPE() và hàm INTERCEPT() thì khác với giải thuật
của hàm LINEST(). Sự khác nhau giữa chúng là có thể
dẫn đến những kết quả khác nhau
đối với những dữ liệu cùng nằm trên
một đường thẳng và chưa được
xác định. Ví dụ, nếu những điểm
dữ liệu của đối số known_y's là 0 và
của known_x's là 1:
* SLOPE() và INTERCEPT() sẽ trả về lỗi #DIV/0!
bởi vì giải thuật của SLOPE() và INTERCEPT() được thiết kế
để tìm ra một và chỉ một đáp án, mà trong
trường hợp này thì kết quả trả về có
nhiều hơn một đáp án.
* LINEST() trả về kết quả là 0 bởi
vì giải thuật của LINEST() được thiết kế
để tìm ra tất cả những đáp án đúng
với những dữ liệu , mà trong trường
hợp này thì kết quả trả về có nhiều hơn
một đáp án cho những dữ liệu cùng nằm trên
một đường thẳng, và trong trường
hợp này thì có ít nhất một đáp án được
tìm thấy.
Ví dụ 1:
Với tập hợp known_y's
= {2, 3, 9, 1, 8} và known_x's = {6, 5, 11, 7, 5}. Không cần dùng
đồ thị, tính hệ số góc của
đường thẳng hồi quy ?
SLOPE({2, 3, 9, 1, 8}, {6, 5, 11, 7, 5}) = 0.305555556
Ví dụ 2:
Đây là ví dụ đã nói đến ở bài Hàm FORECAST()
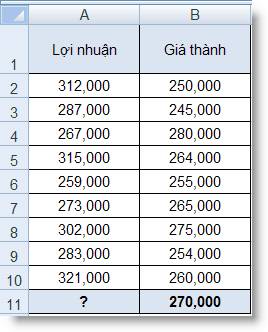
Dựa vào bảng phân tích lợi nhuận
dựa theo giá thành ở bảng sau. Hãy ước
lượng mức lợi nhuận khi giá thành = $270,000 ?
Ta sẽ dùng hàm SLOPE() kết
hợp với hàm INTERCEPT() để tính, bằng phương
pháp dự báo hồi quy tuyến tính đơn (y = ax + b),
với các dữ liệu phụ thuộc là Lợi
nhuận, và các dự liệu độc lập là Giá thành:
a = SLOPE(A2:A10, B2:B10) = -0.24021693
b =
INTERCEPT(A2:A10, B2:B10) = 353,669.9277
x = 270,000
y = (ax + b) = (-0.24021693)*(270,000) + (353,669.9277) = 288,811 (làm
tròn không lấy số lẻ)
Vậy, khi giá thành bằng $270,000
thì mức lợi nhuận (ước lượng) là
$288,811
Để ý rằng, kết quả này bằng với
kết quả của hàm FORECAST()
1. Hàm Tương quan
& Hồi quy tuyến tính
Hàm TREND()
Trả về các trị theo xu hướng tuyến tính. Làm
cho một đường thẳng (dùng phương pháp
bình phương tối thiểu) thích hợp với các
mảng known_y's và known_x's, và TREND() trả về
các giá trị y theo đường thẳng
đó.
TREND() là một hàm cho ra kết quả là một mảng, do
đó nó phải được nhập ở dạng công
thức mảng.
Cú pháp: = TREND(known_y's,
known_x's, new_x's, const)
Known_y's : Một tập
hợp các giá trị y đã biết, trong mối quan
hệ y =
mx + b.
- Nếu mảng known_y's
nằm trong một cột, thì mỗi cột của known_x's
được hiểu như là một biến độc
lập.
- Nếu mảng known_y's nằm trong một dòng, thì
mỗi dòng của known_x's được hiểu
như là một biến độc lập.
Known_x's :
Một tập hợp tùy chọn các giá trị x đã biết, trong
mối quan hệ y = mx + b.
- Mảng known_x's có thể bao
gồm một hay nhiều tập biến. Nếu chỉ
một biến được sử dụng, known_x's
và known_y's có thể có hình dạng bất kỳ,
miễn là chúng có kích thước bằng nhau. Nếu có
nhiều biến được sử dụng, known_y's
phải là một vectơ (là một dãy, với
chiều cao là một dòng, hay với độ rộng là
một cột)
- Nếu bỏ qua known_x's, known_x's sẽ
được giả sử là một mảng {1, 2, 3, ...}
với kích thước bằng với known_y's.
New_x's :
Là các giá trị x mới, dùng để TREND()
trả về các giá trị y tương ứng.
- New_x's phải gồm
một cột (hay một dòng) cho mỗi biến
độc lập, giống như known_x's. Vì thế,
nếu known_y's nằm trong một cột đơn,
thì known_x's và new_x's phải có cùng số
lượng các cột; nếu known_y's nằm trên
một dòng đơn, thì known_x's và new_x's phải
có cùng số lượng các dòng.
- Nếu bỏ qua new_x's, new_x's sẽ
được giả sử giả sử là giống
như known_x's.
- Nếu bỏ qua cả known_x's và new_x's sẽ
được giả sử là mảng {1, 2, 3, ...} với
kích thước bằng với known_y's.
Const :
Là một giá trị logic cho biết có nên ép hằng số b để nó bằng
0 hay không (trong mối quan hệ y = mx + b).
- Nếu const là TRUE (1)
hoặc bỏ qua, b được tính bình
thường.
- Nếu const là FALSE (0), b được gán
bằng 0, khi đó các giá trị m sẽ
được điều chỉnh để y =
mx.
Lưu ý:
o Có thể dùng TREND()
để làm thích hợp các đường cong đa
thức bằng việc quy vào biến có nhiều lũy
thừa khác nhau. Ví dụ, giả sử cột A chứa
các trị y và cột B chứa
các trị x. Khi đó có thể
nhập x^2 trong cột C, x^3 trong cột D, v.v... và tính
hồi quy các cột B, C, D... theo cột A.
o Khi nhập hằng
mảng cho đối số, như hằng mảng cho known_y's
chẳng hạn, dùng dấu phẩy để phân cách các
trị trên cùng dòng, và dấu chấm phẩy để phân
cách các dòng.
Ví dụ 1:
Đây mà một bảng dữ
liệu về lợi tức từ tháng thứ nhất
đến tháng thứ mười hai của một
đơn vị. Xem hai ví dụ về hàm TREND() như sau:
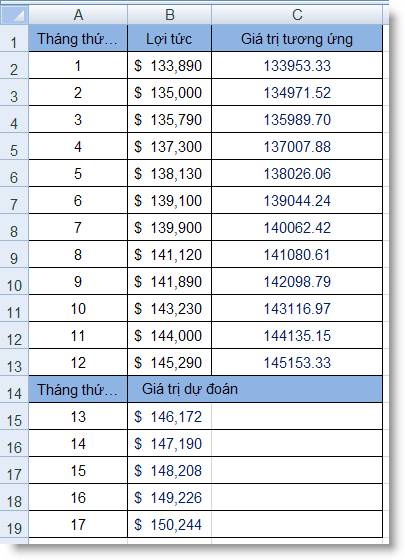
Để tìm giá trị
tương ứng với các giá trị đã có, chọn
cả khối cell C2:C13, nhập công thức mảng:
{=TREND(B2:B13, A2:A13)}
Để tìm các giá trị lợi
tức dự đoán cho các tháng từ 13 đến 17,
chọn khối cell B15:B19, nhập công thức mảng:
{=TREND(B2:B13, A2:A13, A15:A19)}
Ví dụ 2:
Đây là ví dụ đã nói đến trong bài Hàm FORECAST()
Dựa vào bảng phân tích lợi
nhuận dựa theo giá thành ở bảng sau. Hãy ước
lượng mức lợi nhuận khi giá thành = $270,000 ?
Thay vì dùng hàm FORECAST(), ta có thể dùng TREND():
A11 = TREND(A2:A10, B2:B10, B11) = $288,811
Qua ví dụ này, ta thấy rằng,
dùng hàm TREND() hay hàm FORECAST() cũng sẽ có kết quả
tương đương. Hai hàm này chỉ khác nhau ở
chỗ đặt giá trị dùng để dự đoán
trong công thức, TREND() thì đặt giá trị này (new_x's)
ở cuối, còn FORECAST() thì đặt giá trị này (x)
ở đầu.
1. Hàm Tương quan
& Hồi quy tuyến tính
Hàm LOGEST()
Trong phân tính thống kê, LOGEST tính đường cong hàm
mũ phù hợp với dữ liệu được cung
cấp, rồi trả về một mảng các giá trị
mô tả đường cong đó. Do kết quả
trả về là một mảng, nên LOGEST() thường
được nhập với dạng công thức
mảng.
Phương trình của đường cong trong hồi quy
tuyến tính đơn là:
![]()
Phương trình của
đường cong trong hồi quy tuyến tính bội là:
![]()
Trong đó, trị phụ thuộc
y là hàm của các
trị độc lập x, các trị m là các hệ số
tương ứng với mỗi giá trị x, và b là hằng số
(const). Nhớ rằng y, x, m cũng có thể là
các vectơ. Mảng mà LOGEST() trả về là:
![]()
Cú pháp: = LOGEST(known_y's,
known_x's, const, stats)
Known_y's : Một tập
hợp các giá trị y đã biết, trong mối quan
hệ y =
b*m^x.
- Nếu mảng known_y's
nằm trong một cột, thì mỗi cột của known_x's
được hiểu như là một biến độc
lập.
- Nếu mảng known_y's nằm trong một dòng, thì
mỗi dòng của known_x's được hiểu
như là một biến độc lập.
Known_x's :
Một tập hợp tùy chọn các giá trị x đã biết, trong
mối quan hệ y = b*m^x.
- Mảng known_x's có thể bao
gồm một hay nhiều biến. Nếu chỉ một
biến được sử dụng, known_x's và known_y's
có thể có hình dạng bất kỳ, miễn là chúng có kích
thước bằng nhau. Nếu có nhiều biến
được sử dụng, known_y's phải là
một vectơ (là một dãy, với chiều cao là
một dòng, hay với độ rộng là một cột)
- Nếu bỏ qua known_x's, known_x's sẽ
được giả sử là một mảng {1, 2, 3, ...}
với kích thước bằng với known_y's.
Const :
Là một giá trị logic cho biết có nên cho hằng số b bằng 1 hay không
- Nếu const là TRUE (1)
hoặc bỏ qua, b được tính bình
thường.
- Nếu const là FALSE (0), b được gán
bằng 0, và các giá trị m sẽ được điều
chỉnh để y = m^x.
Stats :
Là một giá trị logic cho biết có trả về
thống kê hồi quy phụ hay không
- Nếu stats là FALSE (0)
hoặc bỏ qua, LOGEST() chỉ trả về các hệ
số m và hằng số b.
- Nếu stats là TRUE (1), LOGEST() trả về thống
kê hồi quy phụ, và mảng được trả
về sẽ có dạng:
![]()
Thống kê hồi quy phụ
như sau:
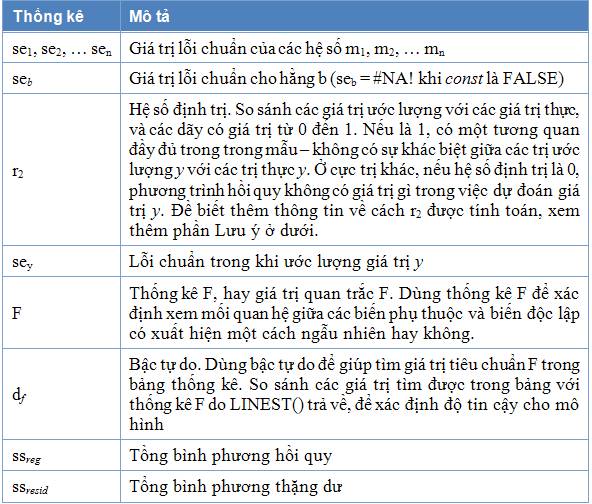
Bảng minh họa sau đây cho
biết thứ tự thống kê hồi quy phụ trả
về:
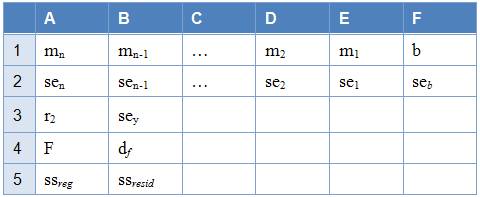
Lưu ý:
o Đồ thị
dữ liệu càng giống đường cong hàm mũ,
đường tính được càng giống với
dữ liệu. Như hàm LINEST(), hàm LOGEST cũng trả về một
mảng các giá trị để mô tả mối quan hệ
giữa các giá trị đó; sự khác biệt giữa hai
hàm này là, LINEST() dùng cho đường thẳng, còn
LOGEST() dùng cho đường cong hàm mũ.
o Khi chỉ có một
biến độc lập x, có thể tìm hệ số góc m và trị b trên trục y (tung độ)
một cách trực tiếp bằng cách dùng các công thức
sau đây:
Hệ số góc m: = INDEX(LOGEST(known_y's,
known_x's), 1)
Điểm cắt (hay tung độ) b: = INDEX(LOGEST(known_y's,
known_x's), 2)
Cũng có thể dùng phương
trình y =
b*m^x
để dự đoán giá trị tương lai của y, tuy nhiên Excel đã
cung cấp hàm GROWTH() để làm điều này rồi.
o Khi nhập hằng
mảng cho đối số, như known_y's chẳng
hạn, dùng dấu phẩy để phân cách các trị trên
cùng một dòng, và dấu chấm phẩy để phân cách
các dòng khác nhau. Nhưng cần chú ý là các ký tự phân cách (dấu
phẩy và dấu chấm phẩy) còn tùy thuộc vào các
thiết lập trong hệ thống bạn đang sử
dụng (các thiết lập cho List seperator trong Customize
Regional Opitions của Control Panel).
o Chú ý rằng các
trị y dự đoán
được từ phương trình hồi quy có thể
không đúng nếu vượt ra ngoài dãy giá trị dùng
để xác định hàm.
o Các phương pháp
kiểm tra phương trình bằng LOGEST() cũng
tương tự như các phương pháp dùng cho LINEST(). Tuy nhiên, thống kê mà LOGEST() trả
về lại dựa vào mô hình tuyến tính sau:
![]()
Nên nhớ điều này khi tính
toán các thống kê hồi quy phụ, đặc biệt là
các trị sei và seb, vì chúng
được so sánh với ln mi và ln b, chứ không phải
là so sánh với mi và b.
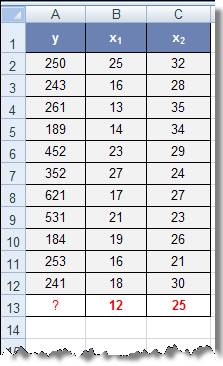
Ví dụ:
Có một bảng dữ liệu
sau. Với số liệu này, dự báo giá trị y khi x1 =
12 và x2 = 25 ?
Ở đây giả sử các
đại lượng y, x1 và x2 có mối quan hệ hàm
mũ với nhau:
![]()
Cách giải:
Chọn khối cell A15:C19, gõ công
thức mảng:
= LOGEST(A2:A12, B2:C12, 1, 1)
Ta sẽ có kết quả như
hình sau:
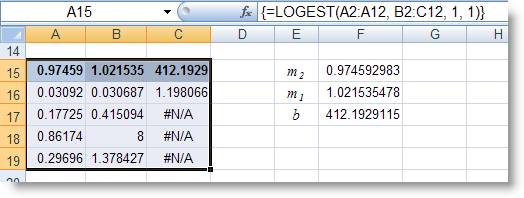
Dựa vào bảng minh họa cho
biết thứ tự thống kê hồi quy phụ trả
về, suy ra được các trị m1, m2 và b như
ở các ô E15:F17.
Áp dụng phương trình của đường cong trong
hồi quy tuyến tính bội, với x1 = 12 và x2 = 25,
bằng công thức tại ô A13:
A13 = F17 * (F16^B13) * (F15^C13) = 279.720291 ≈ 280
Vậy khi x1 = 12 và x2 = 25 thì có
thể dự báo được y = 280
1. Hàm Thống kê
Hàm PERCENTILE()
Tính phân vị thứ k của các giá trị trong một dãy
(trả về nhóm tính theo phần trăm của các giá
trị trong một dãy).
Cú pháp: = PERCENTILE(array,
k)
Array : Là mảng hay dãy
dữ liệu định nghĩa vị trí tương
đối.
k :
Là giá trị phân vị trong khoảng 0 đến 1.
Lưu ý:
o Nếu array
rỗng hay chứa hơn 8191 điểm dữ liệu,
PERCENTILE() sẽ trả về giá trị lỗi #NUM!
o Nếu k không
phải là số, PERCENTILE() sẽ trả về giá trị
lỗi #VALUE!
o Nếu k < 0
hay k > 1, PERCENTILE() sẽ trả về giá trị
lỗi #NUM!
o Nếu k không
phải là bội số của 1/(n-1), PERCENTILE() sẽ
nội suy để xác định giá trị tại phân
vị thứ k.
Ví dụ:
Sau khi thi học kỳ, một
lớp học nọ có số điểm bài thi như sau:
thấp nhất là 6.5 điểm, và cao nhất là 9.25
điểm. Vậy, để muốn lọt vào top 10
của lớp, thì số điểm tối thiểu
phải đạt là bao nhiêu ?
Để lọt vào top 10, nghĩa
là nằm trong nhóm 10% đạt điểm cao của
lớp, hay nói cách khác, phải có điểm thi lớn
hơn hoặc bằng 90% số điểm thi, ta sẽ
dùng hàm PERCENTILE với công thức như sau:
= PERCENTILE({6.5, 9.25}, 0.9) = 8.975
Vậy, điểm bài thi phải
đạt được 8.975 điểm trở lên thì
mới nằm trong top 10 của lớp.
Nói cách khác, điểm số 8.975 nằm trong nhóm "90
Percentile"
Từ ví dụ trên, ta thấy con
số X_percentile được hiểu là lớn
hơn hay bằng X phần trăm...
Chẳng hạn, nếu nói như vầy:
"...Về mặt kinh tế,
với 11 triệu dân, tổng sản lượng quốc
gia (GDP) được ước lượng là 342 tỉ
mỹ kim, và cho mỗi đầu người, khoảng 31
ngàn mỹ kim. Lợi tức trung bình hàng năm cho mỗi
đầu người khoảng 27 ngàn mỹ kim, Hy-lạp
đứng hạng 93 percentile của Âu Châu..."
Thì chúng ta sẽ hiểu rằng
Hy-lạp được xếp hạng cao hơn (hoặc
bằng) 93% tổng số nước của Châu Âu, hay nói
cách khác, Hy-lạp nằm trong nhóm 27% quốc gia dẫn
đầu châu Âu.
1. Hàm Thống kê
Hàm PERCENTRANK()
Trả về hạng của một trị trong một
tập dữ liệu, là số phần trăm của
tập dữ liệu đó, hay nói cách khác là xếp
hạng một trị trong một tập dữ liệu
theo phần trăm của nó trong tập dữ liệu. Hàm
này có thể được dùng để tính vị trí
tương đối của một trị trong tập
dữ liệu. Ví dụ, tính vị trí của điểm
kiểm tra môn toán trong tất cả các điểm kiểm
tra.
Đừng nhầm lẫn hàm này với hàm RANK(). Hàm RANK() cũng trả về hạng của
một trị trong một tập dữ liệu, nhưng
đây là độ lớn của trị này so với các
trị khác trong danh sách.
Cú pháp: = PERCENTRANK(array,
x, significance)
Array : Là mảng hay dãy
dữ liệu định nghĩa vị trí tương
đối.
k :
Là giá trị muốn xếp hạng theo phần trăm.
Significance : Là một giá trị định nghĩa
số ký số có nghĩa (ở phần thập phân) cho
số phần trăm được trả về.
Nếu bỏ qua, PERCENTRANK() dùng giá trị mặc
định là 3 ký số.
Lưu ý:
o Nếu array
rỗng, PERCENTRANK() sẽ trả về giá trị lỗi
#NUM!
o Nếu significance
< 1, PERCENTRANK() sẽ trả về giá trị lỗi #NUM!
o Nếu x không
khớp với một trong các trị trong array,
PERCENTRANK() sẽ nội suy để trả về
hạng đúng của số phần trăm.
Ví dụ:
Có bảng dữ liệu sau
đây:
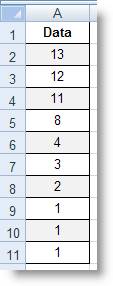
Hạng của số 2 tính theo
phần trăm trong dữ liệu trên (là 0.333, bởi vì có
3 giá trị trong dữ liệu nhỏ hơn 2, và có 6 giá
trị trong dữ liệu lớn hơn 2: 3/(3+6) = 0.333):
= PERCENTRANK(A2:A11, 2) = 0.333 = 33.3%
Hạng của số 4 tính theo
phần trăm trong dữ liệu trên, lấy 2 số
lẻ thập phân:
= PERCENTRANK(A2:A11, 4, 2) = 0.55 = 55%
Hạng của số 8 tính theo
phần trăm trong dữ liệu trên, lấy 4 số
lẻ thập phân:
= PERCENTRANK(A2:A11, 8, 4) = 0.6666 = 66.7%
Hạng của số 5 tính theo phần
trăm trong dữ liệu trên (là 0.583, bằng 1/4 khoảng
cách giữa PERCENTRANK của 4 và PERCENTRANK của 8):
= PERCENTRANK(A2:A11, 5) = 0.583 = 58.3%
1. Hàm Thống kê
Hàm PERCENTRANK()
Trả về hạng của một trị trong một
tập dữ liệu, là số phần trăm của
tập dữ liệu đó, hay nói cách khác là xếp
hạng một trị trong một tập dữ liệu
theo phần trăm của nó trong tập dữ liệu. Hàm
này có thể được dùng để tính vị trí
tương đối của một trị trong tập
dữ liệu. Ví dụ, tính vị trí của điểm
kiểm tra môn toán trong tất cả các điểm kiểm
tra.
Đừng nhầm lẫn hàm này với hàm RANK(). Hàm RANK() cũng trả về hạng của
một trị trong một tập dữ liệu, nhưng
đây là độ lớn của trị này so với các
trị khác trong danh sách.
Cú pháp: = PERCENTRANK(array,
x, significance)
Array : Là mảng hay dãy
dữ liệu định nghĩa vị trí tương
đối.
k :
Là giá trị muốn xếp hạng theo phần trăm.
Significance : Là một giá trị định nghĩa
số ký số có nghĩa (ở phần thập phân) cho
số phần trăm được trả về.
Nếu bỏ qua, PERCENTRANK() dùng giá trị mặc
định là 3 ký số.
Lưu ý:
o Nếu array
rỗng, PERCENTRANK() sẽ trả về giá trị lỗi
#NUM!
o Nếu significance
< 1, PERCENTRANK() sẽ trả về giá trị lỗi #NUM!
o Nếu x không
khớp với một trong các trị trong array, PERCENTRANK()
sẽ nội suy để trả về hạng đúng
của số phần trăm.
Ví dụ:
Có bảng dữ liệu sau
đây:
Hạng của số 2 tính theo
phần trăm trong dữ liệu trên (là 0.333, bởi vì có
3 giá trị trong dữ liệu nhỏ hơn 2, và có 6 giá
trị trong dữ liệu lớn hơn 2: 3/(3+6) = 0.333):
= PERCENTRANK(A2:A11, 2) = 0.333 = 33.3%
Hạng của số 4 tính theo
phần trăm trong dữ liệu trên, lấy 2 số
lẻ thập phân:
= PERCENTRANK(A2:A11, 4, 2) = 0.55 = 55%
Hạng của số 8 tính theo
phần trăm trong dữ liệu trên, lấy 4 số
lẻ thập phân:
= PERCENTRANK(A2:A11, 8, 4) = 0.6666 = 66.7%
Hạng của số 5 tính theo
phần trăm trong dữ liệu trên (là 0.583, bằng 1/4
khoảng cách giữa PERCENTRANK của 4 và PERCENTRANK của
8):
= PERCENTRANK(A2:A11, 5) = 0.583 = 58.3%
1. Hàm Thống kê
Hàm RANK()
Trả về thứ hạng của một trị trong
một tập dữ liệu, là độ lớn của
trị này so với các trị khác trong danh sách. Với
một danh sách đã sắp xếp, thứ hạng của
một số chính là vị trí của số đó trong danh
sách. Hàm này thường được dùng để
xếp vị thứ cho học sinh dựa vào bảng
điểm trung bình.
Đừng nhầm lẫn hàm này với hàm PERCENTRANK(). Hàm PERCENTRANK()() cũng trả về hạng
của một trị trong một tập dữ liệu,
nhưng đây là số phần trăm của tập
dữ liệu đó, hay nói cách khác là xếp hạng
một trị trong một tập dữ liệu theo
phần trăm của nó trong tập dữ liệu.
Cú pháp: = RANK(number,
ref, order)
Number : Là số muốn
tìm thứ hạng của nó.
Ref :
Là mảng, là tham chiếu hay là danh sách các số. Các giá
trị không phải là số trong ref sẽ
được bỏ qua.
Order :
Là một trị logic (0 hay 1) cho biết cách thức sắp
xếp các số hạng trong ref.
- Nếu order là 0 hoặc
bỏ qua, Excel sẽ tính thứ hạng các số như
thể danh sách đã được sắp xếp theo
thứ tự giảm dần (từ lớn tới
nhỏ)
- Nếu order là 1, Excel sẽ tính thứ hạng các
số như thể danh sách đã được sắp
xếp theo thứ tự tăng dần (từ nhỏ
tới lớn)
Lưu ý:
o RANK() sắp xếp
các số giống nhau với cùng một thứ hạng.
Tuy nhiên, sự có mặt của những số giống
nhau sẽ làm ảnh hưởng đến hạng
của các số theo sau. Ví dụ, trong danh sách các số
nguyên, nếu số 10 có hai lần và được
xếp hạng 7, thì số 11 sẽ xếp hạng 9 (không
có hạng 8).
o Muốn RANK() sắp
xếp các số giống nhau với nhưng không cùng
một thứ hạng (thứ hạng sẽ chạy liên
tục không mất số nào), dùng cú pháp sau đây (kết
hợp hàm RANK với hàm COUNT và COUNTIF):
- Với danh sách xếp từ
lớn đến nhỏ:
= RANK(number, ref) + COUNTIF(ref, number)
- 1
-Với danh sách xếp từ
nhỏ đến lớn:
= COUNT(ref) - (RANK(number, ref) +
COUNTIF(ref, number)) + 2
Ví dụ 1: So
sánh một số cách dùng hàm RANK
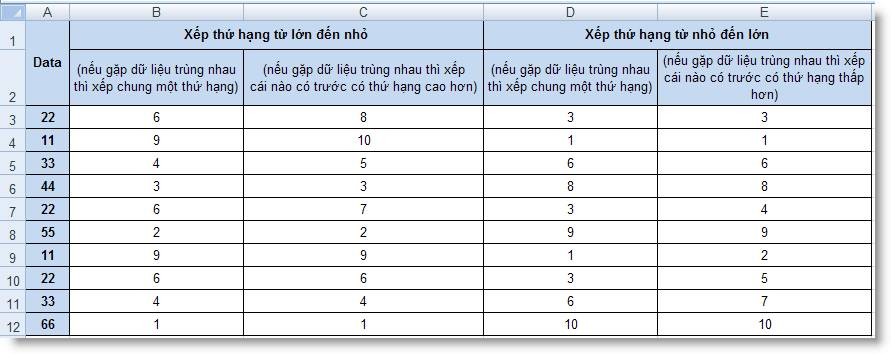
Công thức ở B3:B12 = RANK(A3, $A$3:$A$12)
Công thức ở C3:C12 = RANK(A3, $A$3:$A$125) + COUNTIF(A3:A$12,
A3) - 1
Công thức ở D3:D12 = RANK(A3, $A$3:$A$12, 1)
Công thức ở E3:E12 = COUNT($A$3:$A$125) - (RANK(A3,
$A$3:$A$12) + COUNTIF(A3:A$12, A3)) + 2
Ví dụ 2: Sắp
xếp lại một danh sách theo thứ tự từ
thấp đến cao
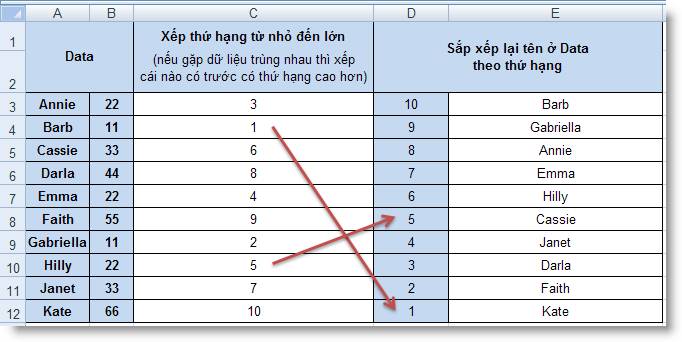
Công thức ở C3:C12 = COUNT($B$3:$B$125) - (RANK(B3,
$B$3:$B$12) + COUNTIF(B3:B$12, B3)) + 2
Công thức ở E3:E12 = OFFSET(A$3, MATCH(SMALL(C$3:C$12, ROW() -
ROW(E$3)+1), C$3:C$12, 0) - 1, 0)
Ví dụ 3: Sắp
xếp lại một danh sách theo thứ tự từ cao
đến thấp
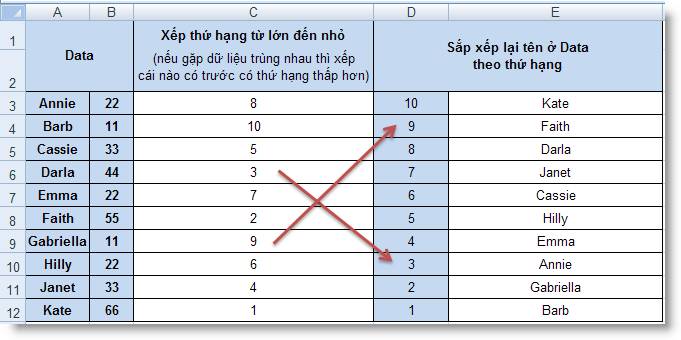
Công thức ở C3:C12 = RANK(B3, $B$3:$B$125) + COUNTIF(B3:B$12,
B3) - 1
Công thức ở E3:E12 = OFFSET(A$3, MATCH(SMALL(C$3:C$12, ROW() -
ROW(E$3) + 1), C$3:C$12, 0) - 1, 0)
Ví dụ 4: Sắp
xếp lại một danh sách theo hai bảng dữ liệu
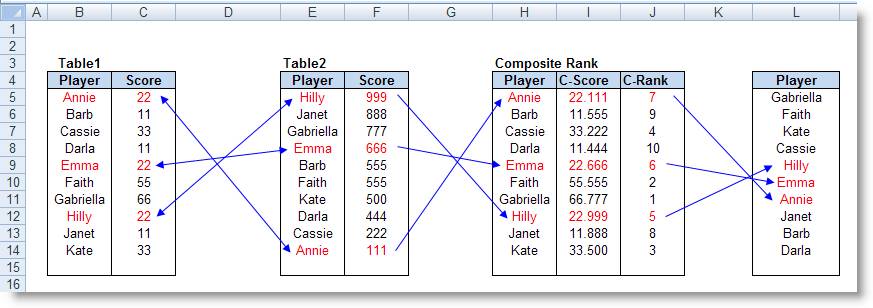
Công thức ở I5:I14 = VLOOKUP(H5, $B$4:$C$14, 2, 0) +
(VLOOKUP(H5, $E$5:$F$14, 2, 0) / 1000) + (ROW() / 1000000)
Công thức ở J5:J14 = RANK(I5, $I$5:$I$14) + COUNTIF($I$5:I5,
I5) - 1
Công thức ở L5:L14 = OFFSET(B$5, MATCH(SMALL(J$5:J$14, ROW() -
ROW(L$5) + 1), J$5:J$14, 0) - 1, 0)
---------------------------------------------------------------------------
